
Einleitung: Jenseits von Text und Code
Die Entwicklung der Künstlichen Intelligenz hat einen entscheidenden Wendepunkt erreicht. Während die frühen 2020er Jahre von reinen Textmodellen (LLMs) dominiert wurden, erleben wir im Jahr 2026 den Siegeszug der Multimodalen KI. Diese Technologie bricht die Barrieren zwischen verschiedenen Datentypen auf und ermöglicht es Maschinen, die Welt so wahrzunehmen, wie wir Menschen es tun: durch das gleichzeitige Sehen, Hören und Lesen.
In diesem ausführlichen Guide analysieren wir die Architektur, die praktischen Anwendungen und die tiefgreifenden Auswirkungen der multimodalen Intelligenz auf unsere Gesellschaft und Wirtschaft.
1. Was ist Multimodale KI? Eine Definition
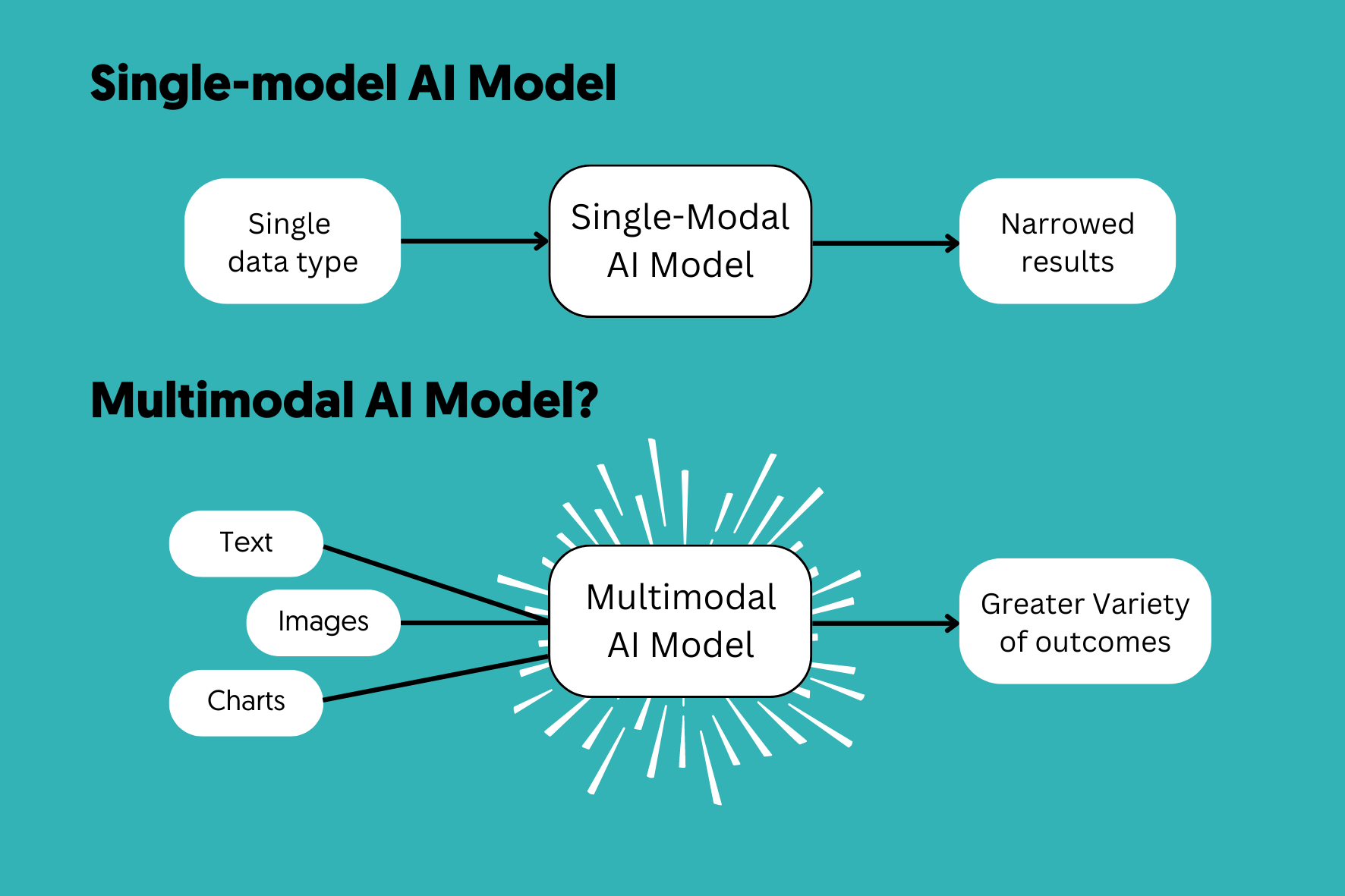
Multimodale KI bezeichnet ein System des maschinellen Lernens, das in der Lage ist, Informationen aus verschiedenen „Modalitäten“ (Datenquellen) gleichzeitig zu verarbeiten und miteinander in Beziehung zu setzen.
Zu diesen Modalitäten gehören:
- Text: Natürliche Sprache, Programmcode und strukturierte Daten.
- Visuelle Daten: Bilder, Videos, Wärmebilder und 3D-Scans.
- Audio: Sprache, Musik und Umgebungsgeräusche.
- Sensorik: LiDAR, GPS-Daten und biometrische Signale.
Im Gegensatz zur unimodalen KI, die nur eine Sprache spricht, ist die multimodale KI ein polyglottes System, das den Kontext zwischen einem gesprochenen Satz und einem gleichzeitig gezeigten Bild versteht.
2. Die technische Architektur: Wie Daten verschmelzen
Um eine echte multimodale Intelligenz zu erreichen, müssen Daten unterschiedlicher Natur mathematisch „abgeglichen“ werden. Dies geschieht in drei Hauptphasen:
2.1 Encoding (Kodierung)
Jeder Datentyp wird durch spezialisierte Encoder in Vektoren (Einbettungen) umgewandelt. Ein Vision Transformer (ViT) verarbeitet Bilder, während ein Transformer-Modell den Text kodiert. Im Jahr 2026 nutzen Spitzenmodelle wie GPT-4o native Multimodalität, bei der alle Daten von Anfang an im selben neuronalen Raum verarbeitet werden.
2.2 Data Fusion (Datenfusion)
Die Fusion ist das Herzstück der Technologie. Es gibt drei Ansätze:
- Early Fusion: Daten werden bereits auf der Eingangsebene kombiniert.
- Late Fusion: Jede Modalität wird separat verarbeitet, und die Ergebnisse werden am Ende zusammengeführt.
- Hybrid Fusion: Der Goldstandard für 2026. Informationen werden während des gesamten Verarbeitungsprozesses zwischen den Schichten ausgetauscht.
3. Warum Multimodale KI den Markt dominiert
Der Vorteil liegt in der kontextuellen Tiefe. Ein rein textbasiertes Modell könnte den Satz „Schau dir das an“ nicht interpretieren. Eine multimodale KI analysiert den Kamerastream und weiß sofort, worauf der Benutzer zeigt.
Vorteile auf einen Blick:
- Höhere Genauigkeit: Durch den Abgleich von Bild und Ton werden Fehler reduziert.
- Natürliche Interaktion: Nutzer können per Sprache, Gestik oder Bild mit der KI kommunizieren.
- Robustheit: Wenn eine Datenquelle unklar ist (z. B. verrauschtes Audio), kann die KI auf eine andere Quelle (z. B. Lippenbewegungen im Video) ausweichen.
4. Anwendungsbereiche in der Industrie 2026
4.1 Medizin: Der KI-Radiologe
In der modernen Diagnostik kombiniert die multimodale KI die Patientenakte (Text), Laborwerte (Zahlen) und MRT-Bilder (Visuell), um Diagnosen mit einer Präzision von über 98 % zu erstellen.
4.2 Automobilindustrie: Autonomes Fahren Level 5
Selbstfahrende Autos im Jahr 2026 verlassen sich nicht mehr nur auf Kameras. Sie fusionieren LiDAR-Punktwolken, akustische Signale (wie Sirenen von Krankenwagen) und visuelle Straßenschilder in Millisekunden.
4.3 E-Commerce: Die virtuelle Umkleidekabine
Kunden können ein Foto von sich hochladen und der KI sagen: „Kombiniere das mit einer sportlichen Jacke“. Die KI versteht den Stil des Fotos und die textliche Anforderung, um ein perfektes visuelles Ergebnis zu generieren.
5. Vergleich: Unimodale vs. Multimodale KI
| Merkmal | Unimodale KI | Multimodale KI |
|---|---|---|
| Dateneingabe | Nur ein Typ (z.B. Text) | Mehrere Typen (Bild, Ton, Text) |
| Verständnis | Oberflächlich / Syntaktisch | Tiefgreifend / Kontextuell |
| Interaktion | Meist Textbasiert | Multimodal (Stimme, Video) |
| Rechenaufwand | Moderat | Sehr hoch |
E-Tablolar’a aktar
6. Herausforderungen: Rechenleistung und Datenschutz
Trotz des Fortschritts gibt es Hürden:
- Rechenkosten: Das Training multimodaler Modelle erfordert massive GPU-Ressourcen (wie Nvidias Blackwell-Architektur).
- Datenausrichtung: Es ist schwierig, hochwertige Datensätze zu finden, bei denen Video, Ton und Text perfekt synchronisiert sind.
- Ethik und Deepfakes: Die Fähigkeit, Stimmen und Gesichter perfekt zu imitieren, stellt eine Gefahr für die Cybersicherheit dar.
7. Rank Math SEO-Strategie für diesen Artikel
Damit dieser Artikel auf Google.de rankt, beachten Sie diese Tipps:
- H1-Überschrift: Muss das Fokus-Keyword enthalten.
- Interne Verlinkung: Verlinken Sie auf Ihre Artikel über Quantum AI oder Edge AI.
- Alt-Texte für Bilder: Verwenden Sie Beschreibungen wie „Multimodale KI Funktionsweise“.
- LSI-Keywords: Nutzen Sie Begriffe wie „Künstliche Intelligenz“, „Deep Learning“ und „Neuronale Netze“.
- Snippet-Optimierung: Halten Sie die URL kurz:
ihreseite.de/multimodale-ki-guide.
8. Fazit: Der Weg zur AGI
Die multimodale KI ist der bisher größte Schritt in Richtung Artificial General Intelligence (AGI). Indem wir Maschinen beibringen, die Welt mit allen Sinnen zu erfahren, schaffen wir eine Brücke zwischen menschlicher Intuition und digitaler Logik. Wer im Jahr 2026 online sichtbar sein will, muss die Komplexität und die Chancen dieser Technologie verstehen.
1 Kommentar zu „Multimodale KI: Die Revolution der Künstlichen Intelligenz im Jahr 2026“