
الذكاء الاصطناعي متعدد الوسائط: الثورة القادمة في عام 2026
مقدمة: ما وراء النصوص والبيانات التقليدية
لقد وصلت مسيرة تطور الذكاء الاصطناعي إلى نقطة تحول تاريخية. لقد تجاوزنا عصر الأنظمة أحادية الوسائط التي كانت تقتصر على معالجة نوع واحد من البيانات، لننتقل بشكل كامل إلى عصر الذكاء الاصطناعي متعدد الوسائط (Multimodal AI). في عام 2026، أصبحت قدرة الآلة على الإدراك والفهم والاستجابة لأنواع متعددة من البيانات — مثل النصوص والصور والأصوات والفيديو — في وقت واحد هي المعيار العالمي الجديد.
في هذا الدليل الشامل، سنغوص في الهندسة التقنية، والتطبيقات الصناعية، والأثر الاجتماعي لهذه التكنولوجيا التي تعيد صياغة علاقتنا بالعالم الرقمي.
1. ما هو الذكاء الاصطناعي متعدد الوسائط؟ التعريف والمفهوم
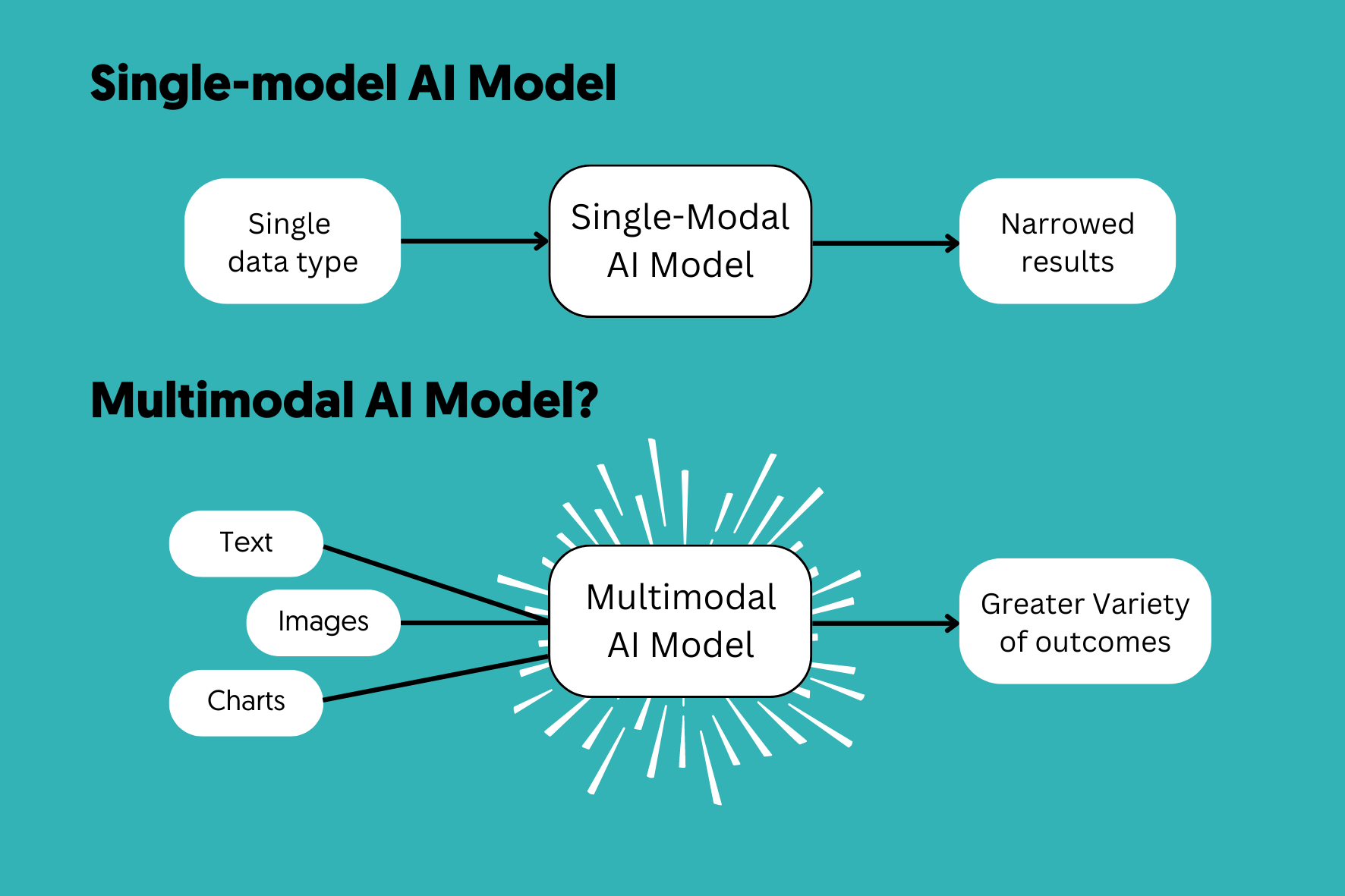
الذكاء الاصطناعي متعدد الوسائط هو نوع من تعلم الآلة حيث يتم تدريب النماذج على تفسير المعلومات من خلال “وسائط” مختلفة. والوسيط هو طريقة محددة يتم من خلالها تسجيل التجربة رقمياً.
تشمل هذه الوسائط ما يلي:
- النصوص: اللغات الطبيعية، الأكواد البرمجية، والبيانات الوصفية.
- الرؤية: الصور الثابتة، بث الفيديو المباشر، والبصمات الحرارية.
- الصوت: الكلام البشري، الضوضاء المحيطة، والترددات فوق الصوتية.
- بيانات الاستشعار: إحداثيات GPS، بيانات LiDAR، والإشارات الحيوية.
على عكس الذكاء الاصطناعي التقليدي الذي يعمل كمتخصص معزول، يعمل الذكاء الاصطناعي متعدد الوسائط مثل العقل البشري؛ فهو يدمج جميع الحواس للوصول إلى فهم كلي للسياق.
2. الهندسة التقنية: عملية دمج البيانات (Data Fusion)
لكي يفهم الذكاء الاصطناعي أن صوت “النباح” يتوافق مع صورة “الكلب” في الفيديو، يجب أن يقوم بعملية “محاذاة البيانات”. يعتمد هذا على ثلاث ركائز معمارية:
2.1 الترميز (Encoding)
يمر كل نوع من البيانات عبر “مشفر” خاص به. يتم تحويل الصور إلى ناقلات (Vectors) عبر Vision Transformers (ViT)، بينما يتم معالجة النصوص عبر آليات الانتباه (Attention Mechanisms). في عام 2026، تستخدم النماذج الرائدة مثل GPT-4o هندسة أصلية حيث تُعالج جميع البيانات في مساحة متجهة مشتركة منذ البداية.
2.2 آليات الدمج (Fusion Mechanisms)
الدمج هو قلب الذكاء الاصطناعي متعدد الوسائط. هناك ثلاث طرق رئيسية:
- الدمج المبكر (Early Fusion): يتم دمج البيانات في مرحلة الإدخال.
- الدمج المتأخر (Late Fusion): يتم معالجة كل وسيط على حدة ودمج النتائج في النهاية.
- الدمج الهجين (Intermediate Fusion): وهو المعيار الحالي، حيث تتفاعل الوسائط باستمرار في الطبقات المخفية للشبكة العصبية.
3. لماذا يهيمن الذكاء الاصطناعي متعدد الوسائط على السوق في 2026؟
تكمن تفوق هذه الأنظمة في العمق السياقي. نموذج النصوص وحده لا يمكنه تفسير جملة “انظر إلى هذا”. أما الذكاء الاصطناعي متعدد الوسائط فيحلل بث الكاميرا ويعرف بالضبط ما يشير إليه المستخدم.
المزايا الرئيسية:
- الدقة السياقية: يقلل من “الهلوسة” الرقمية عبر مطابقة المعلومات من قنوات متعددة.
- التفاعل الطبيعي: يسمح للبشر بالتواصل عبر الصوت والإيماءات والرؤية، وليس فقط لوحات المفاتيح.
- المرونة: إذا كانت إحدى قنوات البيانات مشوشة (مثلاً صوت ضعيف)، يمكن للذكاء الاصطناعي الاعتماد على قناة أخرى (مثل قراءة الشفاه بصرياً) للحفاظ على الدقة.
4. التطبيقات الصناعية في عام 2026
4.1 الصحة: التشخيص الدقيق متعدد الوسائط
في مجال الطب، يدمج الذكاء الاصطناعي متعدد الوسائط السجل الطبي (نص)، والتحاليل الحيوية (بيانات)، والأشعة (صور) لتقديم تشخيصات بدقة تتجاوز 98%، واكتشاف الأمراض قبل ظهور الأعراض بسنوات.
4.2 السيارات: القيادة الذاتية من المستوى الخامس
تدمج السيارات ذاتية القيادة في 2026 بيانات LiDAR والكاميرات والمستشعرات الصوتية للتنقل في الظروف الجوية القاسية، والتعرف ليس فقط على الأشياء، بل على النوايا البشرية بناءً على الحركة.
4.3 التجارة والتعليم الشخصي
أنظمة تعليمية تقرأ إجابة الطالب، ولكنها تحلل أيضاً تعابير وجهه عبر الكاميرا لاكتشاف الإحباط أو الملل، وتعديل وتيرة الدرس تلقائياً.
5. تحديات تقنية وأخلاقية
بالرغم من قوته، يواجه الذكاء الاصطناعي متعدد الوسائط تحديات كبيرة:
- التكلفة الحسابية: يتطلب تدريب هذه النماذج بنية تحتية ضخمة (وحدات معالجة الرسوميات NVIDIA Blackwell).
- الخصوصية: معالجة الوجوه والأصوات والنصوص في وقت واحد تزيد من مخاطر تسريب البيانات الخاصة.
- التزييف العميق (Deepfakes): القدرة على إنشاء فيديوهات وأصوات واقعية للغاية تسهل عملية التضليل الإعلامي.
رأي واحد حول “”